分(fēn)布式計算Hadoop簡介
發布時間:2019-02-14
|
浏覽次數:1568次
描述
Hadoop是什麽:Hadoop是一(yī)個開(kāi)發和運行處理大(dà)規模數據的軟件平台,是Appach的一(yī)個用java語言實現開(kāi)源軟件框架,實現在大(dà)量計算機組成的集群中(zhōng)對海量數據進行分(fēn)布式計算。
詳情
Hadoop是什麽:Hadoop是一(yī)個開(kāi)發和運行處理大(dà)規模數據的軟件平台,是Appach的一(yī)個用java語言實現開(kāi)源軟件框架,實現在大(dà)量計算機組成的集群中(zhōng)對海量數據進行分(fēn)布式計算。
Hadoop框架中(zhōng)最核心設計就是:HDFS和MapReduce。HDFS提供了海量數據的存儲,MapReduce提供了對數據的計算。
數據在Hadoop中(zhōng)處理的流程可以簡單的按照下(xià)圖來理解:數據通過Haddop的集群處理後得到結果。
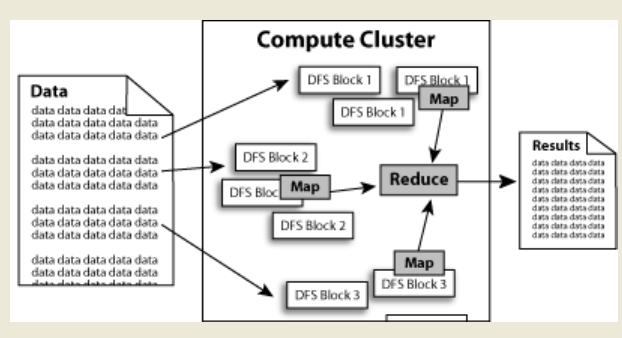
HDFS:Hadoop Distributed File System,Hadoop的分(fēn)布式文件系統。
大(dà)文件被分(fēn)成默認64M一(yī)塊的數據塊分(fēn)布存儲在集群機器中(zhōng)。
如下(xià)圖中(zhōng)的文件 data1被分(fēn)成3塊,這3塊以冗餘鏡像的方式分(fēn)布在不同的機器中(zhōng)。

MapReduce:Hadoop爲每一(yī)個input split創建一(yī)個task調用Map計算,在此task中(zhōng)依次處理此split中(zhōng)的一(yī)個個記錄(record),map會将結果以key--value的形式輸出,hadoop負責按key值将map的輸出整理後作爲Reduce的輸入,Reduce Task的輸出爲整個job的輸出,保存在HDFS上。





